Stand-Alone Systems
Stand-alone software is any software application that does not come bundled with, or require, another software package in order to run. Essentially, it's software that can stand on its own without help from the internet or another computer process.
You would typically install stand-alone software on your computer's hard drive, instead of using it as online software that runs via your internet browser.
Examples of popular stand-alone software include Quicken and Microsoft Money. These two software packages don't require anything more than the operating system on your computer, whether it's Windows or another operating system.
Different Types of Stand-Alone Software
Stand-alone software has certain defining characteristics. The following represent a few examples:
- Software that runs on its own without an internet connection. Anti-virus software or financial software (like Microsoft Money) which can be installed on your computer after inserting an installation disc into your computer or laptop disc drive or portable disc drive. This helps you scan for viruses without the chance of an online virus re-infecting your computer. Having Microsoft Money installed on your computer means you can enter transactions at any time, without the need to be logged in to an internet connection.
- Software that isn’t part of a bundle. Many times, software comes with computer hardware or electronic devices that you would use alongside your computer, such as a scanner. The software could serve as a full interface, such as a desktop program that works with a USB-enabled label printer. Otherwise, the software might consist only of a group of files used to install drivers and other files needed to make a peripheral piece of equipment, such as a laser printer, work with your computer. Conversely, a bundle typically means several types of software programs sold together, like the ones you receive already installed as a bundle when you purchase a new computer.
- A program that runs separately from all other computer processes. This type of program doesn’t rely on any other software in order to function. The most common example of this software type is your computer's operating system. While the operating system contains a large number of interrelated files, it runs on its own without needing any online files or other companion software.
- A portable application that doesn’t need to be installed on your computer. An example is a software program that runs on its own using a disc or flash drive. When not in use, you can easily eject the disc or flash drive. You can keep the program self-contained, and it conveniently doesn't take up space on your hard drive. You might keep a program for virus removal on a separate flash drive so that you can use it if your computer stops functioning due to a bad virus. You might also keep the software on your flash drive that can "rescue" your computer by booting it from the flash drive instead of a potentially damaged hard drive.
- An expansion pack for gaming. If you enjoy playing video games online, you know that gaming software offers expansion packs. In most cases, these packs come as “add-ons” to the original game. Add-ons might be new weapons, new characters, new lands, or other new items that can be incorporated into an existing game.
Not all stand-alone software needs to be installed on your hard drive or run from an external device, such as a flash drive or disc. You can run certain small or simple software by running its executable file directly from the file location on your computer. Simply copy the executable file from an external source, save it any place on your computer, then double-click on it with your cursor to run the program.
Pros and Cons
Stand-alone software usually excels at giving you exactly what you need at a detailed level, because it's typically focused on providing a certain solution. Bundled or enterprise software often incorporates several types of functionality and sometimes suffers from trying to provide too many functions, with no depth in any of them.
On the other hand, stand-alone software can create problems if you need to integrate it with other software packages because it was built to be used alone, and not as an add-on to other software.
Distributed Systems
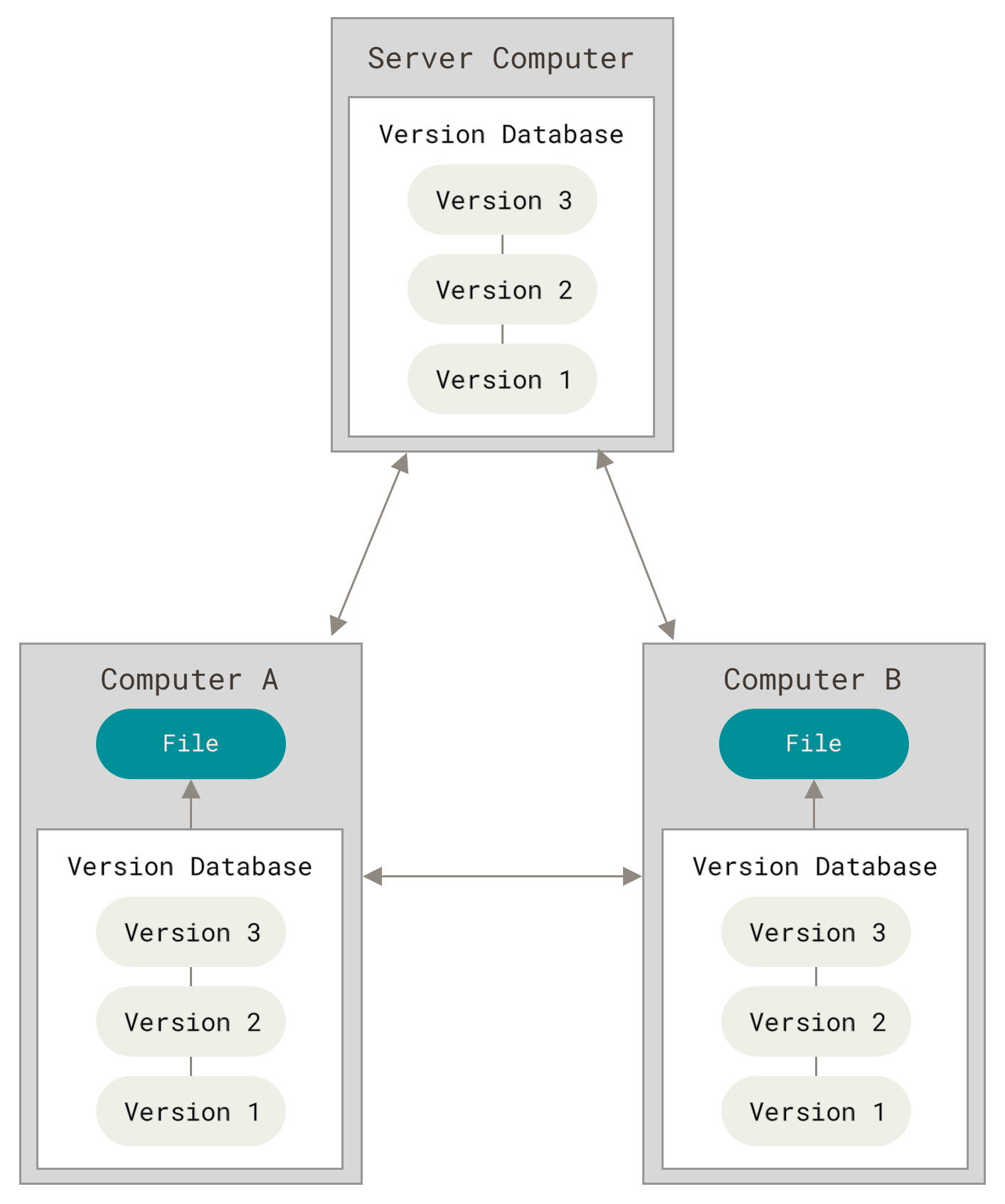
A distributed system contains multiple nodes that are physically separate but linked together using the network. All the nodes in this system communicate with each other and handle processes in tandem. Each of these nodes contains a small part of the distributed operating system software.
A diagram to better explain the distributed system is:
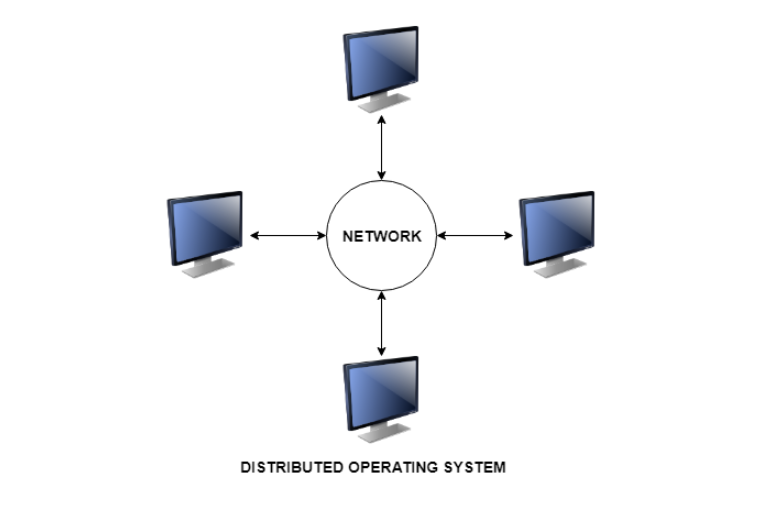
Types of Distributed Systems
The nodes in the distributed systems can be arranged in the form of client/server systems or peer to peer systems. Details about these are as follows:
Client/Server Systems
In client server systems, the client requests a resource and the server provides that resource. A server may serve multiple clients at the same time while a client is in contact with only one server. Both the client and server usually communicate via a computer network and so they are a part of distributed systems.
Peer to Peer Systems
The peer to peer systems contains nodes that are equal participants in data sharing. All the tasks are equally divided between all the nodes. The nodes interact with each other as required as share resources. This is done with the help of a network.
Advantages of Distributed Systems
Some advantages of Distributed Systems are as follows:
- All the nodes in the distributed system are connected to each other. So nodes can easily share data with other nodes.
- More nodes can easily be added to the distributed system i.e. it can be scaled as required.
- Failure of one node does not lead to the failure of the entire distributed system. Other nodes can still communicate with each other.
- Resources like printers can be shared with multiple nodes rather than being restricted to just one.
Disadvantages of Distributed Systems
Some disadvantages of Distributed Systems are as follows:
- It is difficult to provide adequate security in distributed systems because the nodes as well as the connections need to be secured.
- Some messages and data can be lost in the network while moving from one node to another.
- The database connected to the distributed systems is quite complicated and difficult to handle as compared to a single user system.
- Overloading may occur in the network if all the nodes of the distributed system try to send data at once.